Release Notes 2022
6월 OCI Oracle Data Platform 관련 업데이트 소식
Table of Contents
Flexible Compute Shapes are now Available with Data Flow
- Services: Data Flow
- Release Date: June 1, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/data-flow/using/home.htm
서비스 소개
Oracle Cloud Infrastructure Data Flow는 Apache Spark ™ 애플리케이션을 실행하기 위한 완전 관리형 서비스입니다. 개발자가 애플리케이션에 집중할 수 있도록 하고 이를 실행할 수 있는 쉬운 런타임 환경을 제공합니다. 애플리케이션 및 워크플로와의 통합을 위한 API 지원을 통해 쉽고 간단한 사용자 인터페이스를 제공합니다.
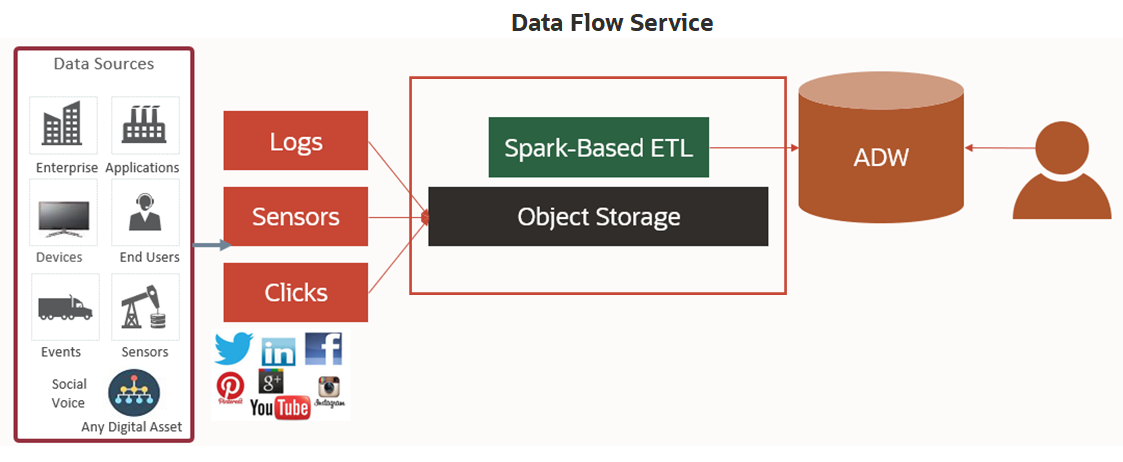
Data Flow 는 Serverless 기반으로 작성된 Application 을 Spark Job 으로 생성하여 Job을 수행할 수가 있습니다. 아래 그림은 Spark Job 을 Serverless 로 수행하기 위한 절차입니다.
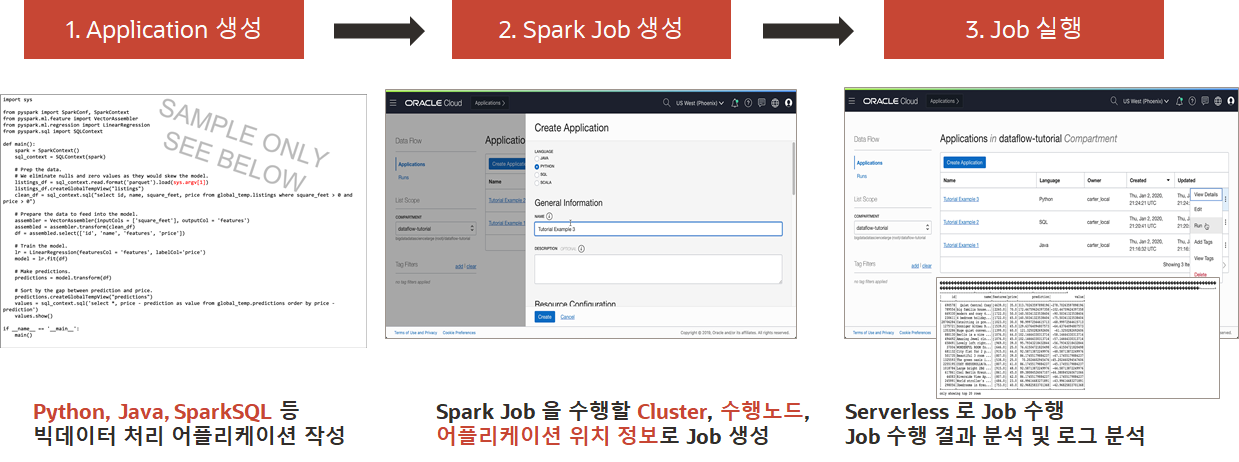
Job 이 수행되고 난 후에는 Job 실행 결과를 확인하고 Log 를 분석하여 처리 결과를 확인하게 됩니다.
신규 기능
다음의 Flexible Compute Shape 들을 지원하게 되었습니다.
- VM.Standard3.Flex (Intel)
- VM.StandardE3.Flex (AMD)
- VM.StandardE4.Flex (AMD)
SQL Explorer
- Services: Operations Insights
- Release Date: June 7, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/operations-insights/doc/data-object-sql-explorer.html
서비스 소개
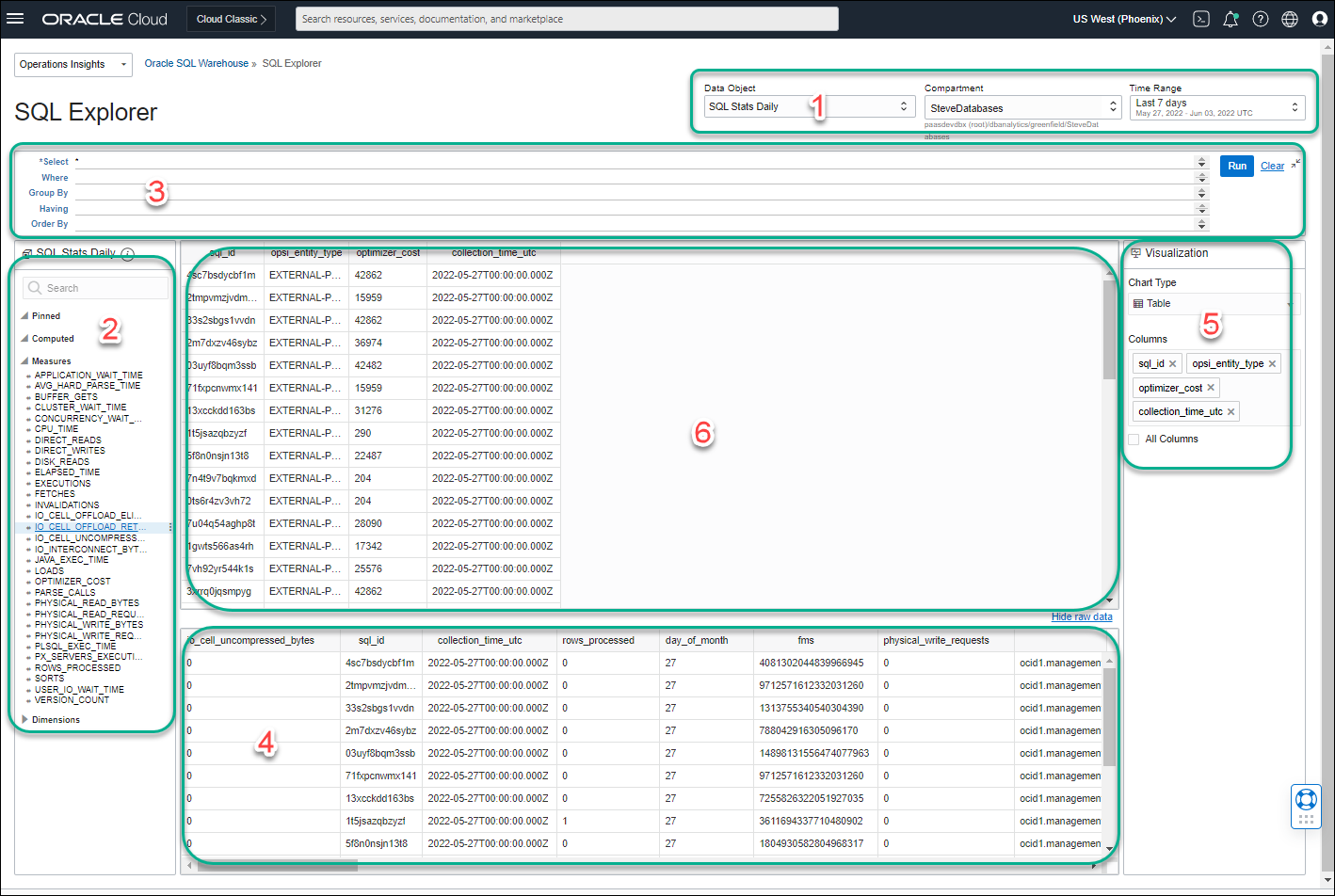
SQL Explorer는 Operations Insights SQL Warehouse에 저장된 자세한 성능 통계를 대화식으로 탐색하고 시각화할 수 있는 사용하기 쉬운 인터페이스를 제공하게 되었습니다.
SQL Explorer UI를 사용하면 SQL 쿼리를 통해 성능 통계를 탐색하여 직관적인 시각화를 만드는 데 사용할 데이터를 추출할 수 있습니다. 쿼리는 raw 데이터 collection 을 캡슐화하고 SQL Explorer에서 쉽게 쿼리할 수 있는 형식으로 결합하는 Operations Insights SQL Warehouse 에 대해 기본적으로 curated view인 데이터 object 를 대상으로 실행됩니다.
UI는 속성 목록에서 열을 선택할 수 있도록 하여 SQL SELECT 문 구성을 단순화합니다. 또는 SQL을 수동으로 입력할 수 있습니다. 자동 완성 기능을 사용하면 쿼리에 대해 SQL을 입력할 수 있으며 SQL 탐색기는 자동으로 속성 열의 인라인 드롭다운 목록을 제공하여 명령문을 완성합니다. SQL 쿼리를 실행하여 원시 데이터를 추출합니다. 구성된 SQL SELECT 쿼리에서 반환된 원시 데이터를 본 다음 이 데이터를 사용하여 쉽게 소비하고 추론을 이끌어낼 수 있는 직관적인 시각화를 만듭니다.
A new release for Database Management is now available!
- Services: Database Management
- Release Date: June 21, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/operations-insights/doc/data-object-sql-explorer.html
서비스 소개
데이터베이스 관리자는 Oracle Cloud Infrastructure Database Management 서비스를 사용하여 Oracle 데이터베이스를 모니터링하고 관리하는 서비스입니다.
신규 기능
이번에 새로이 개선된 Database Management 는 다음을 지원합니다.
- Managed Database Details 페이지의 새 Alert log 섹션에서 관리되는 데이터베이스에 대해 생성된 경고 및 주의 로그 모니터링이 가능해 짐.
- Database Management 의 SQL Tunining Advisor 에 대한 입력으로 SQL 튜닝 집합(STS)을 사용
- Performance Hub에서 ADDM 작업을 생성하고 실행하여 데이터베이스의 현재 또는 과거 성능을 분석
Performance Hub New Feature Run ADDM Task
- Services: Database
- Release Date: June 21, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/Content/Database/Tasks/perfhub.htm
서비스 소개
Performance Hub 는 Database 의 실시간 및 과거 성능 데이터를 볼 수 있습니다.
Base Database Service, Exadata Cloud Service 또는 External Database Service로 관리되는 데이터베이스에서 실행되는 데이터베이스와 함께 Performance Hub를 사용하려면 데이터베이스에 대해 Database Management 를 활성화해야 합니다. Database Management 를 활성화할 때 데이터베이스 관리자는 기본 관리와 전체 관리의 두 가지 옵션 중에서 선택할 수 있습니다.
신규 기능
이제 Performance Hub를 통해 사용자는 ADDM(Automatic Database Diagnostic Monitor) 작업을 생성하고 실행하여 데이터베이스의 현재 또는 과거 성능을 분석할 수 있습니다.
Performance Hub ADDM(Automatic Database Diagnostic Monitor) Tab 에는 ADDM에 의해 저장된 정보에 액세스하기 위한 컨트롤이 포함되어 있습니다. ADDM은 AWR(Automatic Workload Repository) 데이터를 정기적으로 분석한 다음 성능 문제의 근본 원인을 찾고 문제 수정을 위한 권장 사항을 제공하며 애플리케이션의 문제가 없는 영역을 식별합니다. AWR은 과거 성능 데이터의 Repository 이므로 ADDM을 사용하여 문제 발생 시 성능 문제를 재현하는 데 필요한 시간과 리소스를 절약할 수 있습니다.
EM Warehouse
- Services: Operation Insights
- Release Date: June 29, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/operations-insights/doc/em-warehouse.html
서비스 소개
EM(Enterprise Manager) 저장소에는 Enterprise Manager가 모니터링하는 대상에 대한 운영, 성능 및 구성 메트릭과 대상 인벤토리 데이터와 같은 중요한 정보가 포함되어 있습니다. EM Warehouse는 클라우드 기반 도구 및 서비스를 사용하여 이 데이터에 액세스하고 분석할 수 있는 편리한 방법을 제공합니다.
EM Warehouse는 Enterprise Manager 리포지토리 인프라 모니터링 및 구성 메트릭 데이터(하나 이상의 리포지토리에서)를 지속적으로 수집하여 ADW 웨어하우스에 저장합니다. 원시 관측 가능성 및 관리 용이성 데이터에 직접 액세스하여 대상의 현재 및 미래 상태에 대한 통찰력을 얻을 수 있을 뿐만 아니라 대상 전체에서 잡음이 많은 이웃을 찾고 통계 모델을 실행하여 미래 예측을 예측하는 것과 관련된 사용 사례를 해결할 수 있습니다.
신규 기능
Enterprise Manager(EM) Warehouse는 하나 이상의 Enterprise Manager 저장소에서 성능, 구성 및 대상 인벤토리 데이터를 추출하여 Oracle Cloud의 Autonomous Data Warehouse(ADW)에 저장합니다. EM Warehouse를 사용하면 Enterprise Manager 리포지토리의 세부 데이터를 장기간 통합, 분석 및 저장할 수 있습니다.
다음 그림과 같이 EM 리포지토리 데이터는 Cloud Bridge를 통해 테넌시의 OCI Object Storage Bucket으로 업로드됩니다. 여기에서 데이터는 EM Bridge를 통해 Operations Insights Warehouse로 전송됩니다. EM Warehouse는 Operations Insights Autonomous Data Warehouse 내의 스키마입니다.
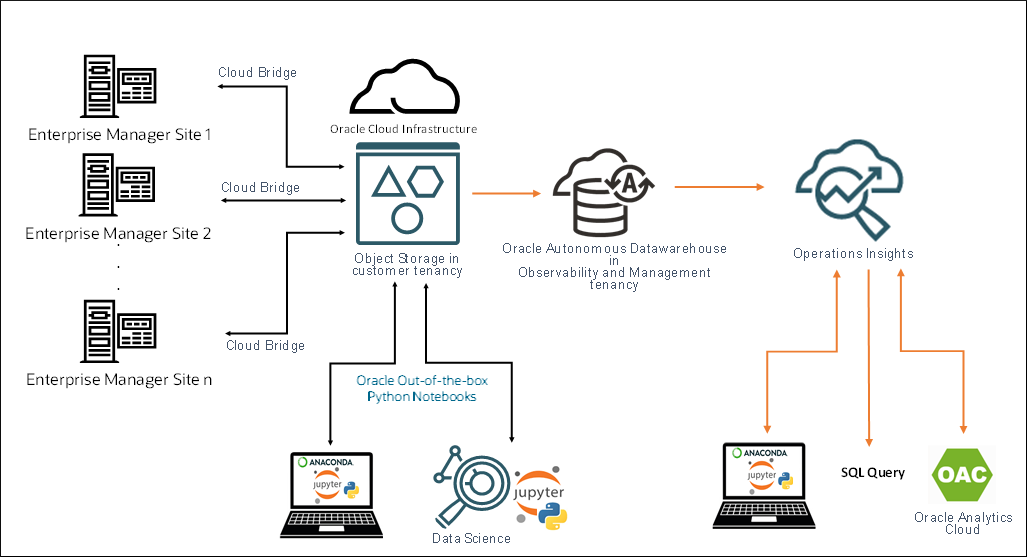

※ Enterprise Manager Warehouse(EM Warehouse) 기능을 사용하려면 OCI Operations Insights Service 라이선스 구독 필요
Spark Dynamic Allocation is now Available with Data Flow
- Services: Data Flow
- Release Date: June 30, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/data-flow/using/dynamic-alloc-about.htm
서비스 소개
Resource 를 절약하고 관리 시간을 줄이기 위해 이제 Data Flow 에서 Spark 을 동적으로 할당할 수 있는 기능이 활성화되었습니다.
데이터 처리를 위한 리소스 계획은 복잡한 작업입니다. 리소스 사용량은 데이터 볼륨의 함수입니다. 매일 데이터의 양은 다양할 수 있으며, 이는 계산 리소스에도 변경이 필요함을 의미합니다.
고정된 수의 Executor 대신 Executor 범위를 기반으로 Data Flow Cluster 를 정의할 수 있습니다. Spark는 워크로드에 따라 애플리케이션이 차지하는 리소스를 동적으로 조정하는 메커니즘을 제공합니다. 애플리케이션은 더 이상 사용되지 않는 리소스를 포기하고 나중에 수요가 있을 때 리소스를 다시 요청할 수 있습니다. 빌링은 애플리케이션에서 리소스를 사용하는 시간만 계산합니다. 반환된 리소스는 빌링되지 않습니다.
신규 기능
리소스를 절약하고 관리 시간을 줄이는 데 도움이 되도록 이제 Data Flow 에서 Spark 동적 할당이 활성화되었습니다. 고정된 수의 실행기 대신 실행기 범위를 기반으로 데이터 흐름 클러스터를 정의할 수 있습니다. Spark는 워크로드에 따라 애플리케이션이 차지하는 리소스를 동적으로 조정하는 메커니즘을 제공합니다.
- Dynamic Allocation 기능을 사용하기 위해서는 아래 방법을 따릅니다.
- 애플리케이션 생성 시 Autoscaling 활성화를 클릭
- 기본 구성은 Spark Configuration property 들에 populated 됨
- 최소 executor 수는 spark.dynamicAllocation.minExecutors 속성값에 해당
- 최대 executor 수는 spark.dynamicAllocation.maxnExecutors 속성값에 해당
- spark.dynamicAllocation.executorIdleTimeout 및 spark.dynamicAllocation.schedulerBacklogTimeout 속성에 대해 다른 값을 입력
Phillsoo Lim RELEASE-NOTES-2022-DATAPLATFORM
oci-release-notes-2022 June-2022 DATABASE