Release Notes 2022
5월 OCI Oracle Data Platform 관련 업데이트 소식
Table of Contents
Operations Insights Demo Mode
- Services: Operations Insights
- Release Date: May 9, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/operations-insights/doc/get-started-operations-insights.html#GUID-047A36C7-D94E-4EF2-86BF-28A76E7AA926
서비스 소개
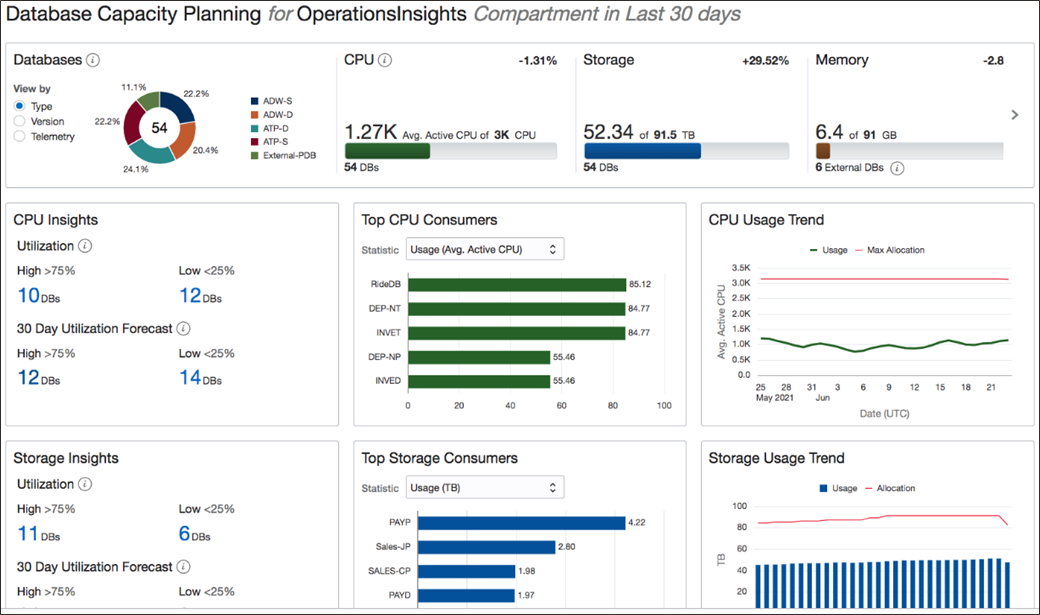
Operations Insights는 데이터베이스 및 호스트의 리소스 활용도와 용량에 대한 360도 통찰력을 제공합니다. CPU 및 스토리지 리소스를 쉽게 분석하고, 용량 문제를 예측하고, 데이터베이스 플릿 전체에서 SQL 성능 문제를 사전에 식별할 수 있습니다.
신규 기능
데모 모드를 사용하면 모니터링되는 환경을 구성할 필요 없이 즉시 Operations Insights 기능을 탐색할 수 있습니다. 데모 모드가 활성화되면 Operations Insights는 리소스에 대한 복잡한 환경 설정없이 다양한 리소스 모니터링 및 분석 기능을 탐색할 수 있는 데이터들로 채워집니다.
데모 모드를 활성화하려면 Operations Insights 개요 페이지로 이동하여 데모 모드 활성화를 클릭합니다. 
데모 모드를 활성화를 클릭하면 다음과 같이 데모 모드 사용을 위한 필요 Policy 설정 적용 화면이 나타납니다. 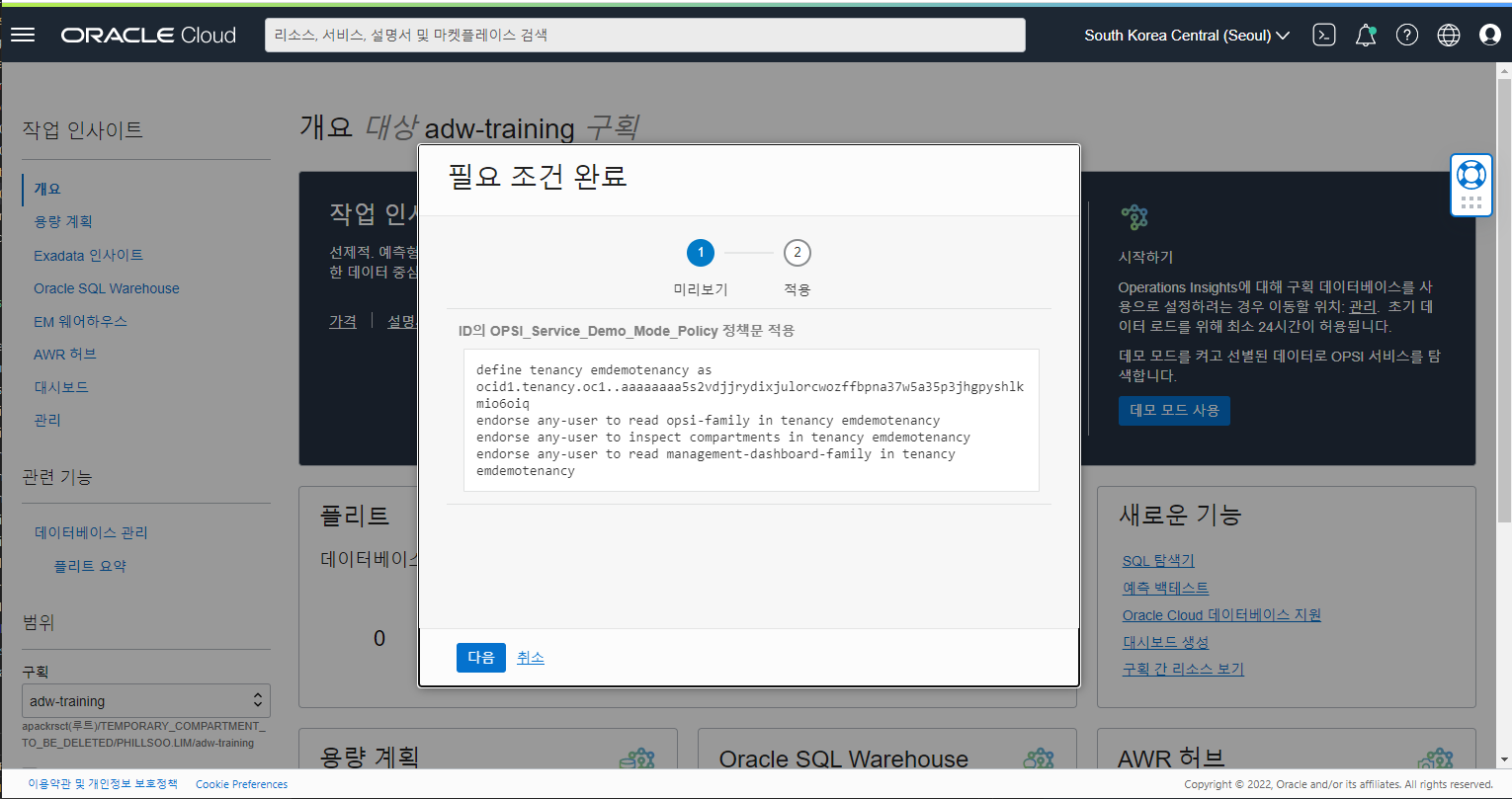
데모 모드 Policy 설정이 완료되면 아래와 같이 별도의 복잡한 환경 설정 작업없이 아래와 같이 분석 기능들을 맛볼 수 있는 데모 모드가 나타납니다. 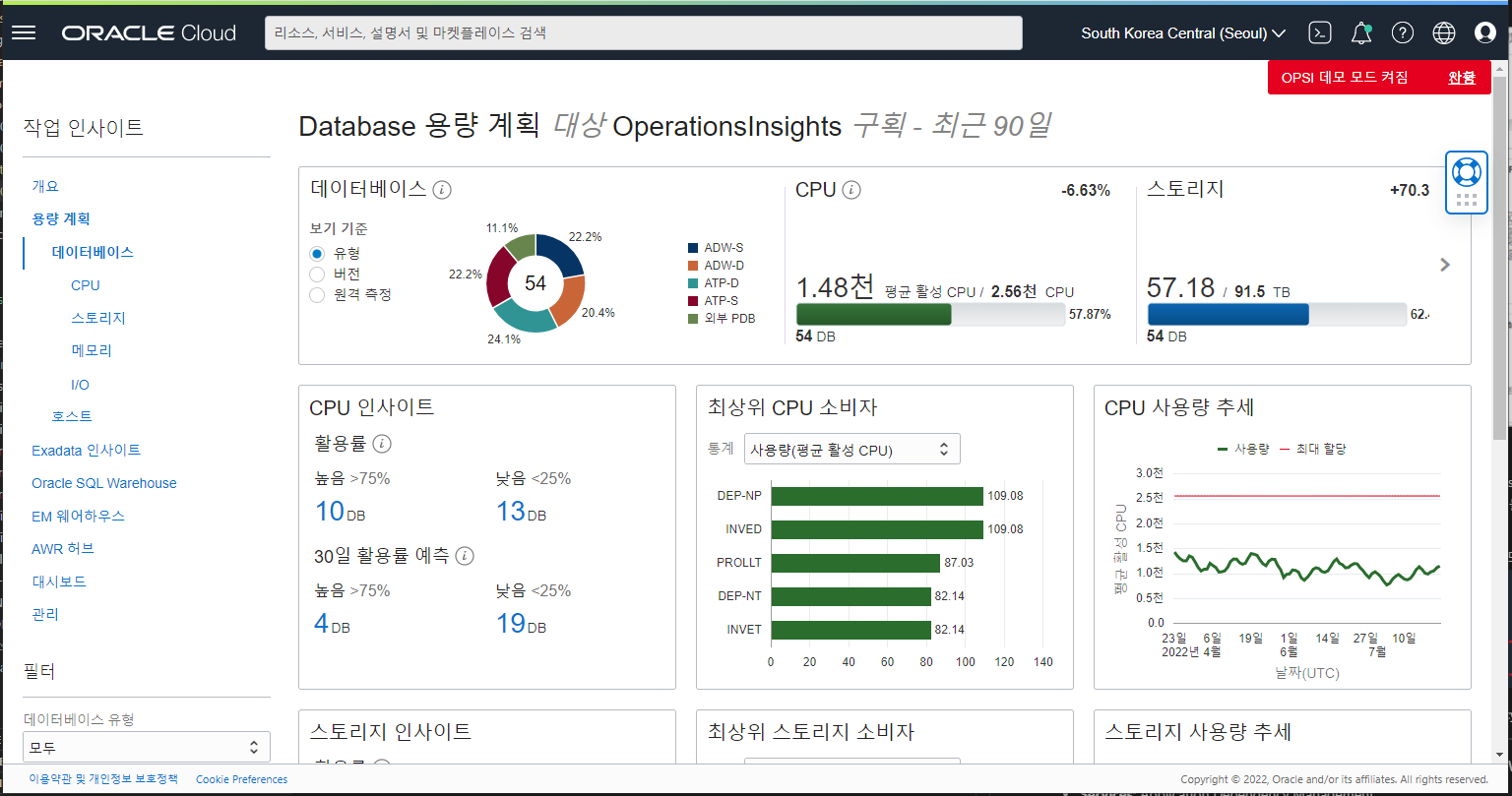
New release for Big Data
- Services: Big Data, Oracle Cloud Infrastructure
- Release Date: May 13, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/Content/bigdata/home.htm
서비스 소개
Big Data Service는 가용성이 높은 전용 Hadoop 및 Spark Cluster를 온디맨드로 프로비저닝해 주는 서비스로써 안전하게 OCI 에서 관리되는 Managed Service 입니다. 작은 규모의 테스트 및 개발 클러스터에서부터 대규모 Production Cluster를 지원하는 다양한 Oracle Cloud Infrastructure 컴퓨팅 Shape들을 사용하여 빅 데이터 및 분석 워크로드에 맞게 클러스터를 확장하는 서비스입니다. Big Data Service 의 신규 버전이 반영되었습니다.
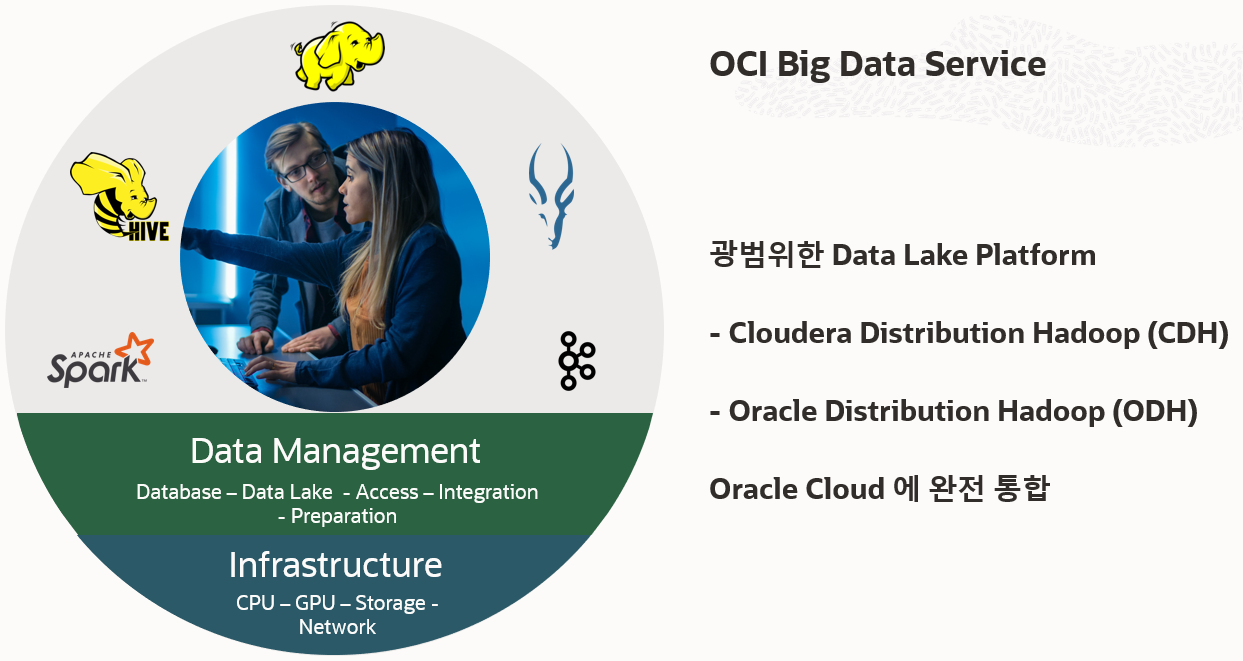
Big Data Service 가 포함하고 있는 사항
- Hadoop 기술 Stack의 선택
- ODH (Apache Hadoop): Apache Hadoop(ODH)을 포함한 Oracle Distribution 설치가 포함된 Hadoop 스택. ODH에는 Apache Ambari, Apache Hadoop, Apache HBase, Apache Hive, Apache Spark 및 빅 데이터 작업 및 보안을 위한 기타 서비스가 포함됩니다.
- CDH (Cloudera Hadoop): Apache Hadoop(CDH)을 포함한 Cloudera Distribution의 전체 설치를 포함하는 Hadoop 스택. CDH에는 Cloudera Manager, Apache Flume, Apache Hadoop, Apache HBase, Apache Hive, Apache Hue, Apache Kafka, Apache Pig, Apache Sentry, Apache Solr, Apache Spark 및 빅 데이터 작업 및 보안을 위한 기타 서비스가 포함됩니다. Big Data Service의 현재 버전에는 CDH 6.3.3이 포함되어 있습니다.
- ID 관리, 네트워킹, 컴퓨팅, 스토리지 및 모니터링을 포함한 Oracle Cloud Infrastructure 기능 및 리소스
- 클러스터 생성 및 관리를 위한 REST API
- bda-oss-admin 스토리지 제공자를 관리하기 위한 명령줄 인터페이스
- 기본 Oracle Cloud Infrastructure 형태를 기반으로 모든 크기의 클러스터를 생성할 수 있는 기능 (ex: 유연한 가상 환경에서 작고 수명이 짧은 클러스터, 전용 하드웨어에서 매우 큰 장기 실행 클러스터 또는 이들의 조합)
- Optional secure, high availablity (HA) 클러스터
- Oracle Cloud SQL 통합 - Oracle SQL 쿼리 언어를 사용하여 Apache Hadoop, Apache Kafka, NoSQL 및 객체 저장소 전반에서 데이터 분석
- Big Data Service 클러스터에 배포된 항목을 사용자 지정할 수 있는 전체 액세스 권한 제공
Hadoop Ecosystem
Open Source Hadoop 은 Hadoop HDFS 및 관리를 위한 Open Source 진영의 다양한 Ecosystem 들이 있습니다. Ecosystem 을 이루고 있는 Tool 들을 역할에 맞는 솔루션을 사용함으로써 완전한 Big Data 시스템을 완성하게 됩니다.
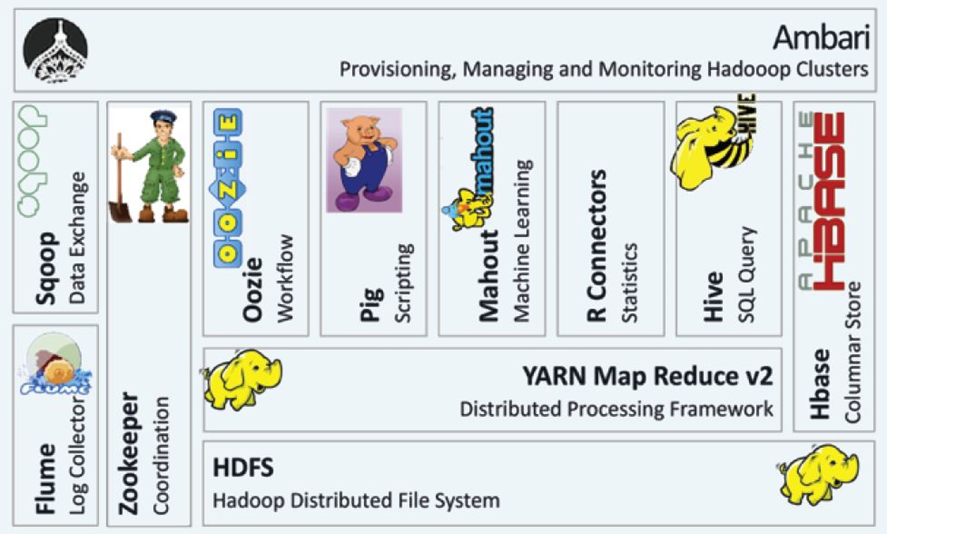
OCI Big Data Cluster
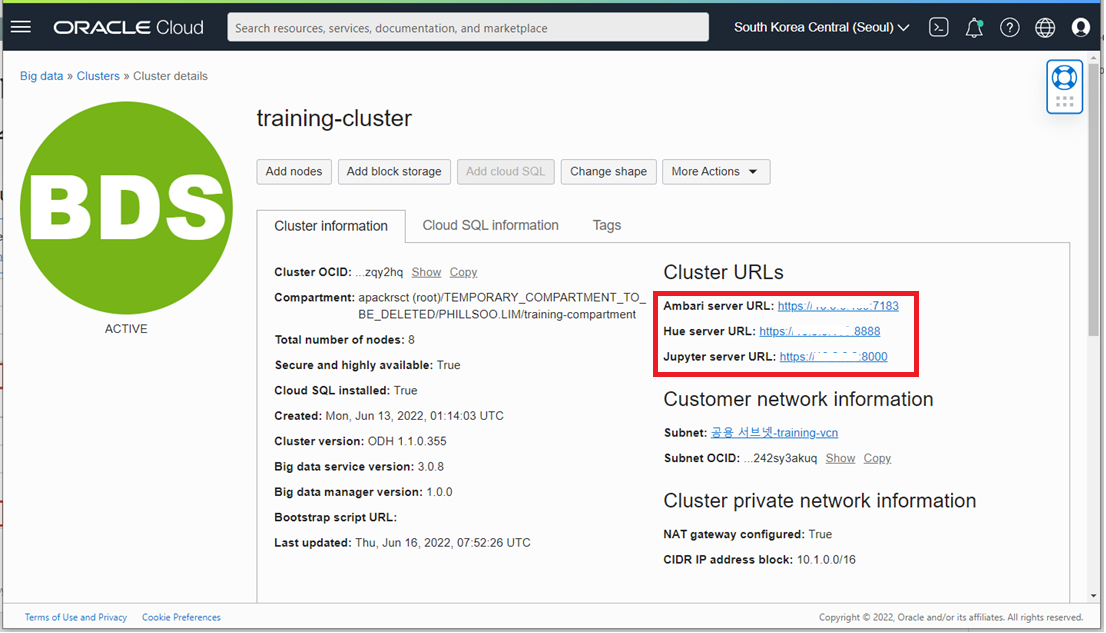
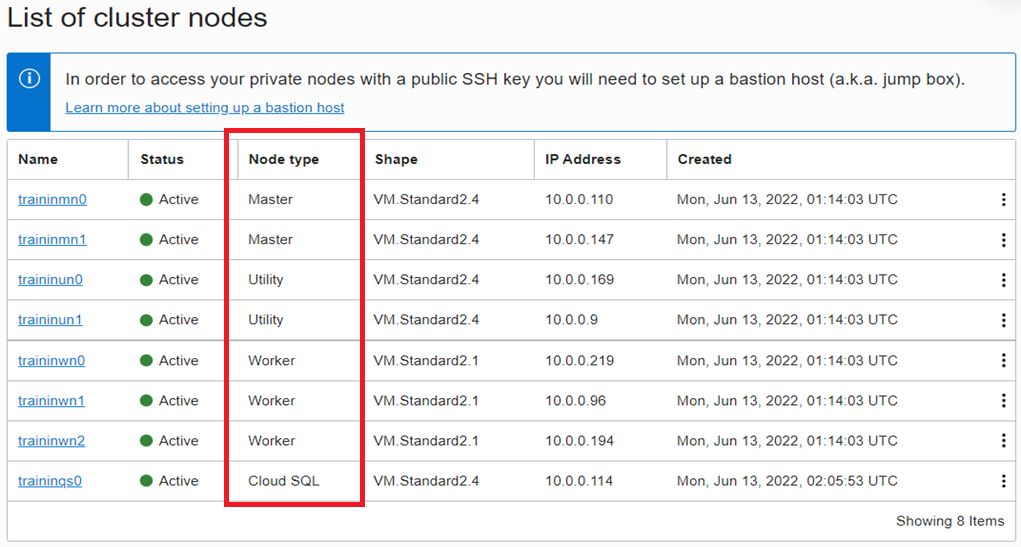
OCI 에서 Managed 서비스로 제공되는 Big Data 서비스는 손쉽게 Cluster 를 One-Click 으로 생성하게 됩니다. Big Data Cluster 생성을 수행하게 되면 노드들의 역할에 따라 Master Node, Utility Node, Master Node, Worker Node 들이 설치되고 각각의 노드에 Ambari, Hue, Jupyter Notebook, Ranger 등의 툴들이 자동 설치가 됩니다. Worker Node 는 용량이 추가 증설이 필요할 경우, 노드를 추가하여 Scale-Out 을 원활하게 수행할 수 있게 지원합니다.
신규 기능 (Big Data 3.0.7)
- ODH 클러스터에서 수평(노드 추가 또는 제거) 및 수직(노드 모양 모양) 자동 크기 조정을 구성
- 각 노드에 필요한 OCPU 및 메모리 수를 지정하려면 자동 크기 조정 중에 E4 Flex Shape 사용
- 클러스터에 컴퓨팅 전용 Worker 노드 추가 기능
- 클러스터에 Worker 노드 삭제 기능
- 클러스터를 생성하는 동안 외부 Kerberos 영역 이름을 제공
- 클러스터를 생성하는 동안 부트스트랩 스크립트 URL을 제공. 이 URL은 클러스터가 생성된 후에도 업데이트될 수 있음
- ODH 클러스터에서 SSL(Secure Socket Layer) 인증서를 활성화하고 사용 가능
- ODH 클러스터에서 Hue, Livy, Jupyter, Jupyterhub 및 Trino를 사용. 기본적으로 클러스터에서 실행되도록 구성됨
New release for Data Integration
- Services: Data Integration, Oracle Cloud Infrastructure
- Release Date: May 16, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/data-integration/home.htm
서비스 소개
Data Integration 은 데이터 엔지니어와 ETL 개발자가 다양한 데이터 자산에서 데이터 수집과 같은 공통 ETL(추출, 변환 및 로드) 작업을 수행하는 데 도움이 되는 Fully Managed Multi tenant 서비스입니다. Integration 할 Source 의 데이터를 정리, 변환 및 재구성하고 Target 데이터 Asset에 효율적으로 로드해 주는 서비스입니다. 이번에 Data Integration 의 신규 버전이 반영되었습니다. 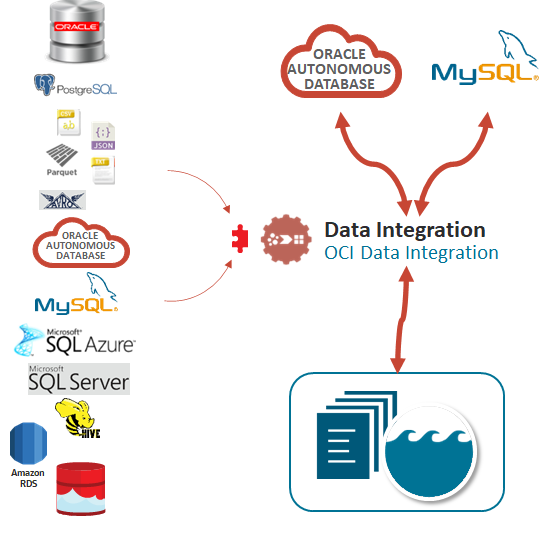

Data Integration Workspace
Data Integration 은 하나의 프로젝트 개념의 관리할 데이터 자산에 대한 등록, 데이터 흐름, 수행을 관리하는 Workspace 라는 기능을 통해 관리합니다.
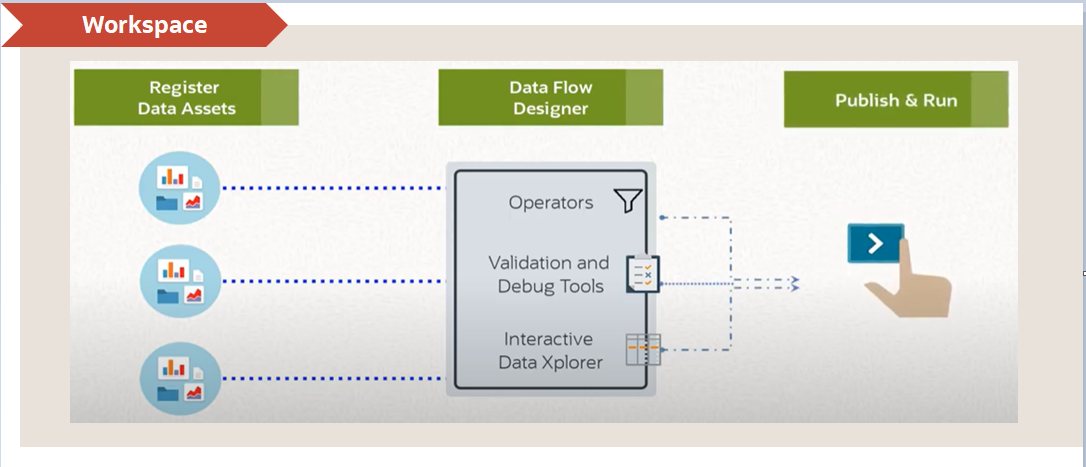
Data Flow 관리
Data Integration 에 등록된 자산들을 기반으로 연계할 Data 의 흐름을 Data Flow Designer 를 통해 아래와 같이 흐름을 디자인합니다.
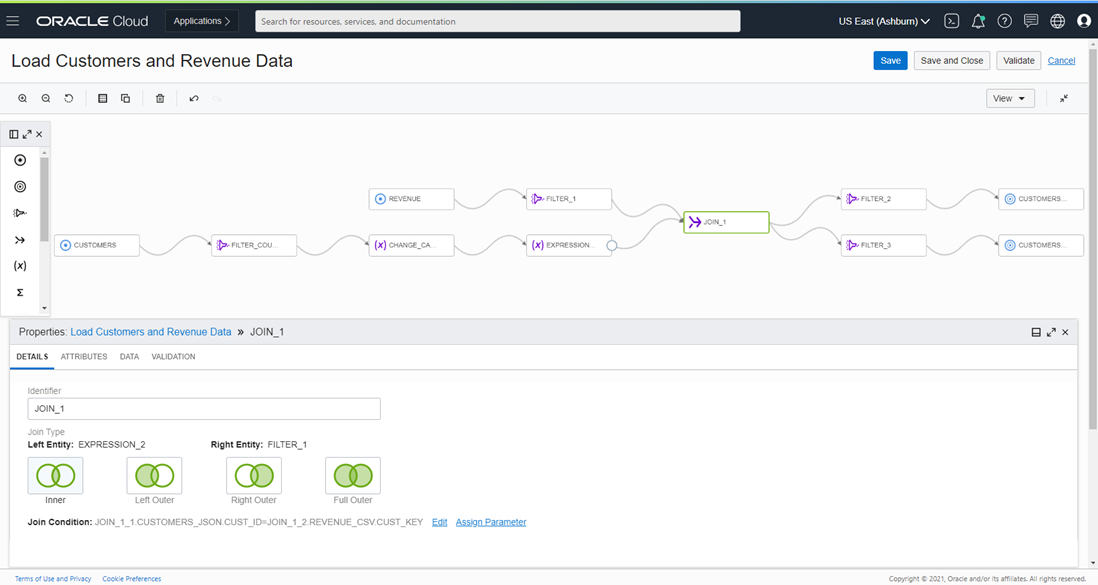
Applicatoin 실행
디자인된 Data Flow 의 데이터 흐름을 기반으로 수행할 ETL Application 을 Job 으로 실행하게 됩니다.
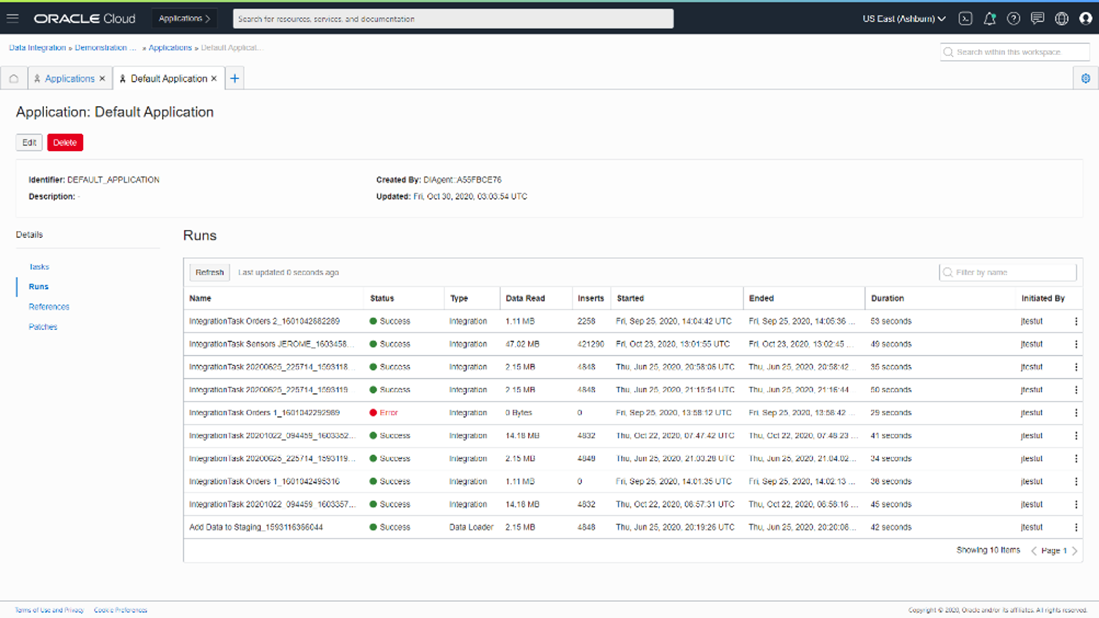
신규 기능
- HDFS(Hadoop Distributed File System)를 데이터 소스 또는 타겟으로 연결
- Data Loader Job 을 사용하여 새 대상 또는 기존 대상으로 로드할 스키마의 여러 데이터 엔터티에서 소스 데이터를 선택
- Data Integration Application 프로그램을 Workspace 내의 다른 구획으로 이동
- Data Integration Application 의 OCID를 복사
- 30분 이상의 간격으로만 트리거되는 실행 일정을 만듬
- 게시된 파이프라인의 작업을 동일한 작업 영역 또는 다른 작업 영역의 다른 애플리케이션에 있는 다른 게시된 작업에 매핑
- Data Flow 에서 소스, 타겟 또는 표현식 연산자를 빠르게 복제
- Data Flow 에서 표현식 연산자와 함께 Runtime 시스템 생성 매개변수를 사용
Forecast Backtesting
- Services: Operations Insights
- Release Date: May 17, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/operations-insights/doc/analyze-database-resources.html#GUID-27B819F2-F926-4ABD-A89B-BEC0DF5C1228__GUID-04481C49-4027-4F37-B476-0A37D7A39D0A
서비스 소개
Forecast Backtesting 을 사용하면 실제 데이터가 수집되는 기간에 대한 과거 Forecast 를 비교하고 과거 추세와 예측 추세 간의 편차를 수량화할 수 있습니다. 이를 통해 다음을 수행하여 예측된 추세의 정확성을 쉽게 테스트하고 예측에 대한 확신을 가지실 수 있습니다.
- 훈련 범위 선택에 대한 Forecasts 의 민감도(sensitivity) 평가
- 이상값(Outliers)에 대한 Forcasts 의 민감도(sensitivity) 평가
- 장거리(longer-range) Forecasts 의 정확성 평가(Training Period 의 1/2 이상)
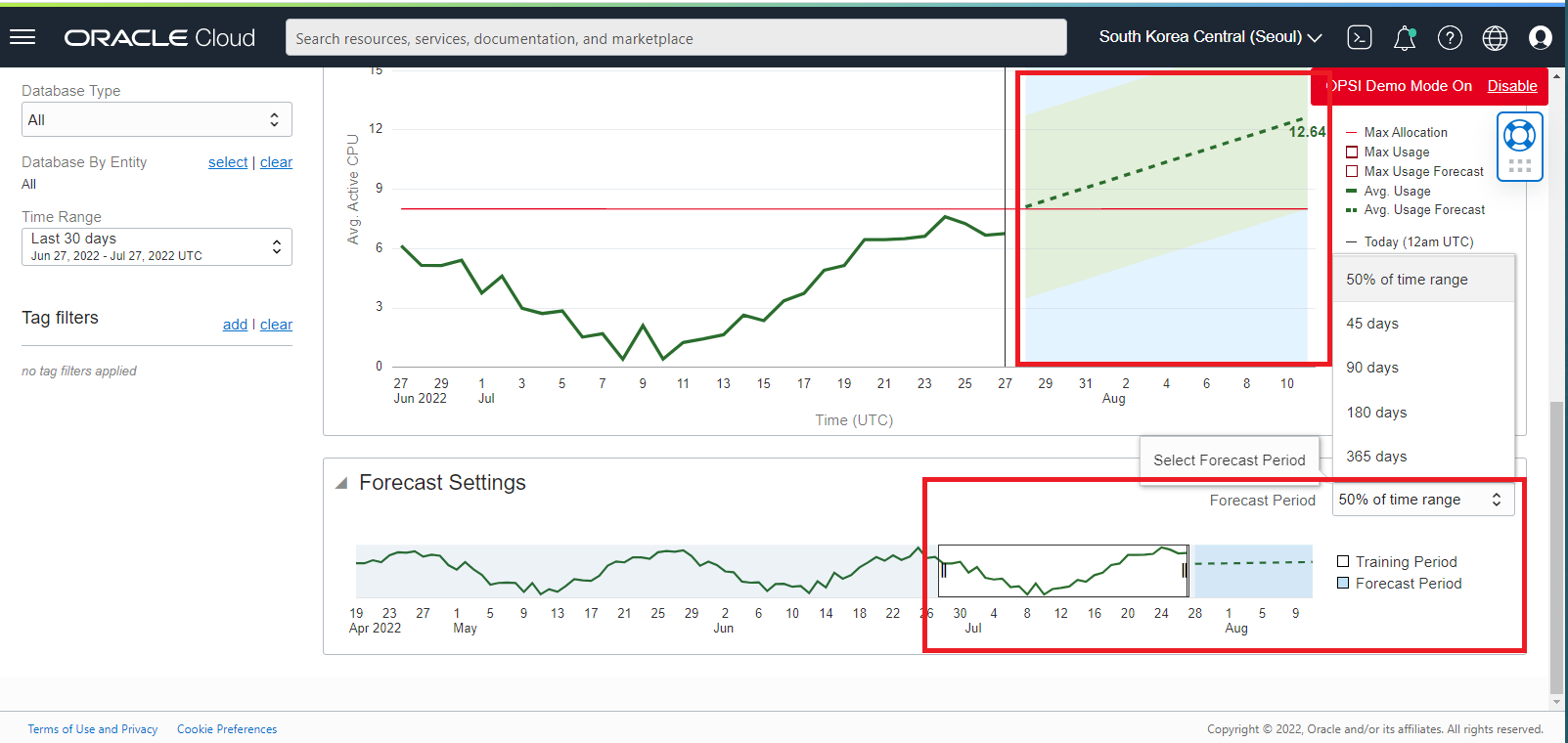
데이터베이스 및 호스트 리소스에 대한 용량 계획(CPU, 스토리지, 메모리, I/O)을 통해 Forecasts Backtesting 을 수행합니다.
추세 및 예측 차트 바로 아래에는 Forecasts 설정이 있습니다. 여기에서 Forecasts 기간(예측할 미래 기간)과 Training 기간(추세를 예측하기 위해 과거 데이터가 사용되는 기간)을 설정합니다. 예측 설정에 대한 변경 사항은 추세 및 예측 차트에 즉시 반영됩니다.
기본적으로 Operations Insights는 Training 기간의 1/2에 해당하는 Forecasts 기간을 생성합니다. 이를 특정 일수(45, 90, 180 및 365)로 설정할 수 있습니다.
A new release for Database Management is now available!
- Services: Database Management
- Release Date: May 31, 2022
- Documentation: https://docs.oracle.com/en-us/iaas/operations-insights/doc/analyze-database-resources.html#GUID-27B819F2-F926-4ABD-A89B-BEC0DF5C1228__GUID-04481C49-4027-4F37-B476-0A37D7A39D0A
서비스 소개
데이터베이스 관리자는 Oracle Cloud Infrastructure Database Management 서비스를 사용하여 Oracle 데이터베이스를 모니터링하고 관리할 수 있습니다.
데이터베이스 관리를 사용하여 컨테이너 데이터베이스(CDB), PDB 및 비컨테이너 데이터베이스(non-CDB)를 포함하는 단일 인스턴스 및 RAC 데이터베이스를 모니터링할 수 있습니다. 데이터베이스 관리는 Oracle 데이터베이스 버전 11.2.0.4 이상을 지원합니다.
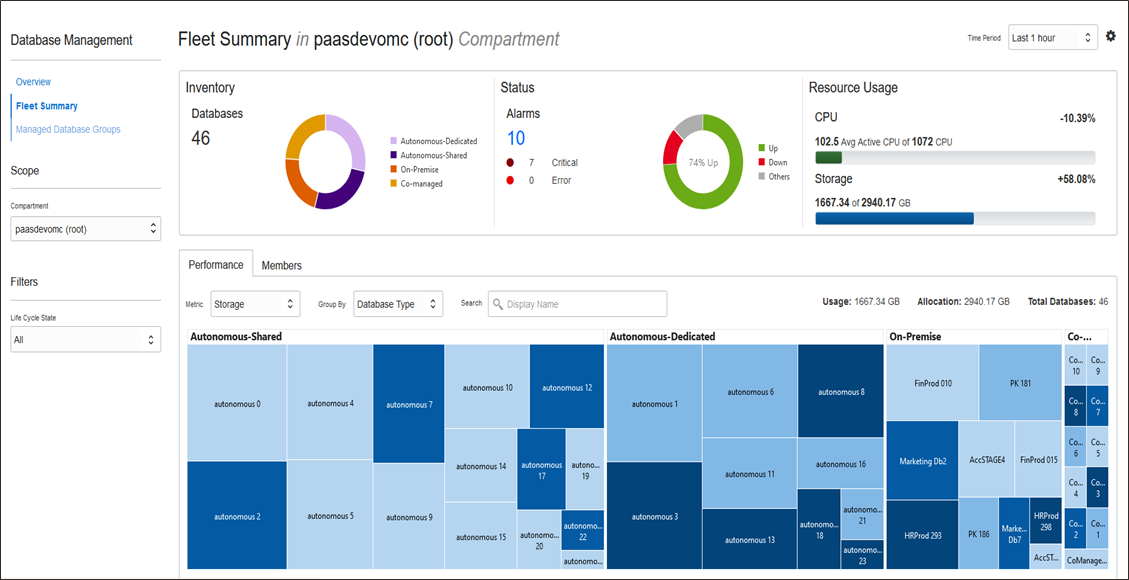
다음은 Database Management 를 사용하여 수행할 수 있는 작업들입니다.
- Oracle Database Fleet 의 주요 성능 및 구성 지표를 모니터링합니다. 또한 선택한 기간 동안 데이터베이스 Matric 을 비교하고 분석할 수 있습니다.
- 성능 문제를 신속하게 진단할 수 있는 데이터베이스 성능의 단일 창 보기를 위해 Performance Hub를 사용할 수 있습니다.
- AWR Explorer를 사용하여 AWR 스냅샷의 과거 성능 데이터를 해석하기 쉬운 차트로 시각화합니다.
- 여러 구획에 상주하는 중요한 Oracle 데이터베이스를 데이터베이스 그룹으로 그룹화하고 모니터링합니다.
- 단일 Oracle 데이터베이스 또는 데이터베이스 그룹에서 관리 작업을 수행하기 위해 SQL 작업을 생성하고 예약합니다.
신규 기능
- 최근 7일 옵션은 이제 Fleet Summary 및 Managed Database Details 페이지의 Time Period 메뉴에서 사용할 수 있습니다. 지난 7일 옵션을 선택하여 집합 요약 페이지에서 데이터베이스 집합의 성능 및 구성 메트릭을 비교하거나 관리되는 데이터베이스 세부 정보 페이지의 요약 섹션에서 지난 7일 동안의 데이터베이스 성능 속성을 모니터링할 수 있습니다.
- Managed Database Details 정보 페이지의 Summary 섹션에 있는 활동 차트가 상자 도표를 사용하여 CPU 사용률을 표시하도록 향상되었습니다. 상자 그림에서 마우스를 가져가면 CPU 사용률의 최대 및 최소 백분율과 같은 추가 세부 정보를 볼 수 있습니다. 마찬가지로 요약 섹션의 I/O 차트도 상자 플롯에 I/O 메트릭을 표시하도록 향상되었습니다.
- Managed Database Details 정보 페이지의 사용자 섹션이 개선되어 사용자 계정의 상태와 사용자 계정이 만료되기까지 남은 일수를 시각적으로 표시합니다. 또한 사용자 세부 정보 페이지에서 리소스 아래의 왼쪽 창에 나열된 옵션을 사용하여 사용자 계정의 역할, 시스템 및 개체 권한과 같은 정보를 볼 수 있습니다. 리소스 아래의 각 옵션 옆에 숫자가 표시되며 이는 사용자 계정에 있는 역할 또는 권한의 수를 나타냅니다.
Phillsoo Lim RELEASE-NOTES-2022-DATAPLATFORM
oci-release-notes-2022 may-2022 DATABASE